Analyse des sons auscultatoires pulmonaires
1. Introduction
Savoir distinguer les sons pulmonaires normaux et anormaux
(sibilants, crépitants, etc ...) est important pour le diagnostic
médical. En effet, les sons respiratoires contiennent de précieuses
informations sur la physiologie et les pathologies des
poumons et des voies aériennes.
On verra plus loin que le phonopneumogramme et le
spectrogramme d'un son enregistré à l'aide d'un stéthoscope électronique peuvent aider à déterminer
l’état du parenchyme pulmonaire, ainsi que les modification pathologiques des voies aériennes.
Parmi les marqueurs connus (sibilants, crépitants,
stridors, ronchis), les travaux publiés se concentrent
principalement sur la détection des crépitants et des sibilants.
Cet article, que nous avons rédigé fin 2006, fait un état des lieux des publications disponibles à cette date, et
des travaux de recherche relatifs à l’auscultation pulmonaire et
surtout aux méthodes d’analyse des sons auscultatoires pulmonaires.
2. Limites de l’audition humaine
Des études ont été réalisées pour tester la capacité de
l’oreille humaine à détecter les crépitants dans un signal auscultatoire.
La méthode utilisée consistait à superposer des crépitants
artificiels à un signal réel. Les résultats indiquent que les erreurs
de détections les plus significatives sont liées aux facteurs suivants:
• l’intensité du signal respiratoire : les respirations amples
masquent d’avantage les crépitants que les respirations superficielles;
• le type de crépitants : les crépitants fins sont plus facilement
reconnaissables car leur forme d’onde diffère d’avantage de
celle des sons pulmonaires classiques;
• l’amplitude des crépitants. On conclue de ces études que la
validation des algorithmes de détection automatique de crépitants
ne devrait pas se reposer sur l’auscultation comme
unique référence.
2.1. Intéręt de l’analyse automatique des sons
À l’inverse, la compréhension des mécanismes sous-jacents
à la production des sons pulmonaires est encore très imparfaite,
et l’enregistrement, puis l’analyse des sons respiratoires
permet d’améliorer cette compréhension ainsi qu’une mise
en relation objective des sons respiratoires anormaux avec une
pathologie respiratoire particulière.
Par ailleurs, une analyse
objective permet le développement de systèmes de classification
qui rendent possible une qualification plus précise des
sons respiratoires normaux et des sons pathologiques.
Alors que
l’auscultation conventionnelle au stéthoscope est subjective et
difficilement partageable, ces systèmes devraient apporter une
aide au diagnostic objective et précoce avec une meilleure sensibilité
et reproductibilité des résultats.
De plus, les applications, y
compris l’évaluation du diagnostic, le monitoring et l’échange de
données par Internet sont des compléments évidents de l’analyse
objective et automatique des sons auscultatoires.
Les outils de
capture permettent le monitoring longue durée des patients à
l’hôpital ou à domicile. Elle pourrait également ętre une solution
utile pour les pays en voie de développement ou les communautés
reculées. Ce type de système a, de plus, l’immense
avantage de conserver le caractère non invasif et peu coűteux de
l’auscultation. Enfin, l’étude de Sestini et al. montre qu’une
association entre le signal acoustique et l’image est utile pour
l’apprentissage et la compréhension des sons pulmonaires par
les étudiants en médecine.
2.2. Propagation des sons pulmonaires
La propagation et la déformation des sons pulmonaires sont
liées à différents facteurs:
• la réponse acoustique du stéthoscope, l’asymétrie des sons
(qui indique la présence d’une éventuelle anomalie ou pathologie),
la composition hétérogène des tissus (os, muscles,
peau. . .) qui agissent comme des filtres ;
• le point d’analyse : les mesures indiquent que les sons
thoraciques sont plus faibles en amplitude que les sons
trachéaux.
2.3. Définition des marqueurs connus
Il existe aujourd’hui de nombreuses définitions différentes
des caractéristiques de marqueurs communs tels que le sibilant
ou le crépitant.
Une sémantique universelle reste à
créer.
Divers travaux ont essayé de collecter les définitions
des termes liés aux sons respiratoires et ont abouti au recensement
de 162 termes utilisés couramment dans le Computer
respiratory sound analysis (CORSA). Cela ne permet cependant
pas aux médecins d’avoir une définition commune des
termes employés et de ce fait, la description des caractéristiques
des sons est encore très imagée. à titre d’illustration,
un sibilant est encore très souvent associé à « un bruit sifflant
» et un crépitant à « un bruit de grain de riz dans une
poęle ».
Et la définition objective (amplitude, gradient, fréquence, durée) est différente pour chaque auteur.
Il existe aujourd’hui de nombreuses définitions différentes
des caractéristiques de marqueurs communs tels que le sibilant
ou le crépitant.
Et la définition objective (amplitude, gradient, fréquence, durée) est différente pour chaque auteur.
2.4. Définition d’une sémiologie
L’article de Rossi et al. fournit des recommandations
relatives aux conditions expérimentales nécessaires à
l’enregistrement de sons respiratoires.
Il définit les conditions
expérimentales optimales (relatives notamment au bruit
ambiant, y compris les sons non respiratoires du sujet, tels que
les sons vocaux) ainsi que les procédures spécifiques au type de
son que l’on désire enregistrer (souffles, toux, ronflements), des
indications pour l’enregistrement (diagnostic, évaluation d’une
thérapie, monitoring), de l’âge du sujet (bébé, enfant, adulte), et
de la méthode d’enregistrement (champ libre, microphone endobronchial).
L’auteur s’appuie sur les męmes recommandations
que celles de l’European Respiratory Society(ERS) pour les
tests des fonctions pulmonaires pour la préparation du sujet. Pour
les enregistrements courts, une position assise est conseillée,
alors qu’une position couchée est généralement préférable pour
des enregistrements longs.
3. Définition des termes
L’article de Sovijari et al. publié dans l’European Respiratory
Journal fournit des définitions précises pour les termes
couramment utilisés dans le domaine de l’auscultation pulmonaire
et de l’analyse des sons. Les plus pertinentes sont rappelées
ci-dessous.
3.1. Sons pulmonaires
• sons respiratoires (breath sound): l'ensemble des sons, normaux et pathologiques enregistrés au niveau de la trachée, des
poumons ou de la bouche. Leur génération est liée au flux d’air dans le système respiratoire. Ils sont caractérisés par un large
spectre sonore, avec une fréquence moyenne dépendant du point d’auscultation;
• sons pathologiques (adventitious sound) : il s’agit de sons
respiratoires additionnels, rajoutés aux sons respiratoires normaux.
Ils peuvent ętre continus (sibilants) ou discontinus
(crépitants). Certains (comme les squawks) possèdent des
caractéristiques des deux. La présence de tels sons est a priori
un indicateur de désordres pulmonaires;
• son bronchique (bronchial sound): ce terme est utilisé dans deux acceptions ; il couvre à la fois les sons respiratoires
normaux qui sont détectés dans la partie antérieure haute des poumons et dont l’intensité est à peu près identique durant
les phases d’inspiration et d’expiration, mais aussi des sons respiratoires anormaux qui sont détectés dans la partie postérieure
des poumons et qui contiennent des composantes de haute fréquence et une intensité plus élevée que les sons respiratoires
normaux enregistrés au męme point. Le passage de son normal à son pathologique est dű à des désordres pulmonaires;
• sons pulmonaires (lung sound): il s’agit de tous les sons enregistrés au niveau du thorax. Ils incluent les sons respiratoires
normaux et les sons pathologiques;
• sons musculaires (muscle sound): il s’agit de sons générés par la contraction musculaire. Ils ont généralement une
fréquence faible (inférieure à 20 Hz) et une faible intensité. L’amplitude et la fréquence des sons musculaires sont liées
à la force de contraction;
• son respiratoire normal (normal breath sound): sur le thorax, un son respiratoire normal est caractérisé par un
bruit faible pendant l’inspiration, et très audible pendant l’expiration. Au niveau de la trachée, le son respiratoire normal
est caractérisé par un large spectre de bruit (par exemple: contenant des composantes haute-fréquence), audible à la fois
durant la phase d’inspiration et celle d’expiration;
• son pleural de friction (pleural friction sound): ces bruits forts résultent du frottement pleuropariétal et viscéral. Leur
présence est le signe d’une inflammation, voire d’un liquide au niveau pleural.
3.2. Marqueurs pathologiques
• crépitants (crackles): ces sons pathologiques, discontinus, explosifs apparaissent généralement dans la phase d’inspiration.
Ils sont caractérisés par leur forme d’onde, leur durée et leur position dans le cycle respiratoire. Un crépitant peut ętre caractérisé
par sa durée totale comme étant un crépitant fin (si sa durée est courte) ou gros (si sa durée est longue). L’apparition de crépitants
révèle généralement des pathologies du tissu pulmonaire, voire des voies de conduction;
• gros crépitant (coarse crackle): crépitant avec un timbre plus grave, une forte amplitude et une longue durée.
2CD supérieur à 10ms (CD:
durée de deux cycles);
• crépitant fin (fine crackle): crépitant avec un timbre plus aigu, une faible amplitude et une courte durée.
2CD inférieur à 10ms;
• toux (cough): il s’agit d’un réflexe respiratoire caractérisé par une soudaine expulsion d’air d’une grande vélocité, accompagné de
sons transitoires de timbre et d’intensité variable. La toux est causée par une irritation des voies de conduction. Une simple toux consiste
en une phase inspiratoire suivie d’un effort expiratoire avec fermeture de la glotte; cette phase est suivie d’une soudaine réouverture de la
glotte avec une rapide expiration du flux d’air. Une toux chronique indique généralement la présence d’une pathologie des voies respiratoires
ou des désordres du tissu pulmonaire;
• sons de toux (cough sound): les sons transitoires induits par les réflexes de toux ont une fréquence comprise entre 50 et 3000 Hz.
Les caractéristiques de ces sons varient en fonction
de la pathologie pulmonaire. Ainsi, les sons de toux qui
contiennent des sibilants sont typiquement des cas d’asthme;
• ronchis (rhonchus): il s’agit d’un sibilant au timbre plus grave, contenant des formes d’ondes périodiques
avec une durée supérieure
à 100 ms et une fréquence inférieure à 300 Hz.
Les ronchis traduisent la présence de sécrétions ou des rétrécissements
des voies aériennes;
• ronflements (snoring sound): il s’agit de bruits respiratoires de basse fréquence avec des
composantes périodiques (fréquence fondamentale
entre 30 et 250 Hz) qui se produisent pendant la phase de sommeil, et sont induit par les vibrations anormales
dans les parois ou l’oropharynx.
Ils sont le plus souvent inspiratoires ; de faibles composantes expiratoires peuvent apparaître chez
les patients atteints d’apnée obstructive du sommeil;
• squawk (squawk): il s’agit de sons inspiratoires pathologiques relativement courts, et qui présentent
un caractère musical. Ils sont
occasionnellement trouvés chez les patients atteints de désordres pulmonaires interstitiels. Acoustiquement,
leur forme d’onde ressemble ŕ de courts sibilants, ils sont souvent
précédés de crépitants. La durée des squawks varie entre
50 et 400 ms;
• stridor (stridor): c’est un son fort, de basse fréquence, qui
trouve son origine dans le larynx ou dans la trachée. Il apparaît
souvent durant l’inspiration. Il peut ętre audible au niveau de
la bouche, de la trachée et des poumons. Les stridors peuvent
apparaître dans les toux asphyxiantes (vibration des structures
laryngées lors de dyspnée) ou les sténoses laryngales ou
trachéales;
• sibilant (wheeze): ce son pathologique, continu, présente
un caractère musical. Acoustiquement, il est caractérisé par
une forme d’onde avec une fréquence dominante généralement
supérieure à 100 Hz et une durée supérieure à 100 ms. De
plus, le son doit inclure au moins dix vibrations successives.
Les sibilants sont généralement associés à l’obstruction des
voies aériennes. Le sibilant est qualifié de monophonique s’il
n’a qu’une fréquence. S’il en contient plusieurs fréquences,
on le qualifie de polyphonique.3.3. Méthodes de visualisation
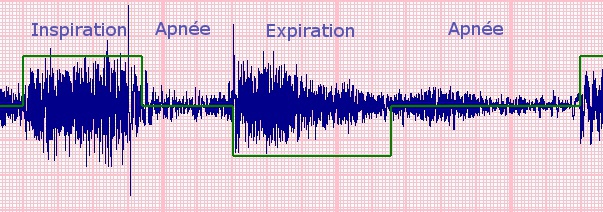
• phonopneumogramme (phonopneumogram): il s’agit de
la représentation de l'amplitude du signal d'auscultation en fonction du temps; la figure ci-dessous représente
un phonopneumogramme
prélevé à l'aide d'un prototype Alcatel-Lucent de stéthoscope et généré par le logiciel
propriétaire de la société. La courbe verte
est le résultat de notre algorithme de détection des phases de respiration
(inspiration, apnée, expiration, apnée).
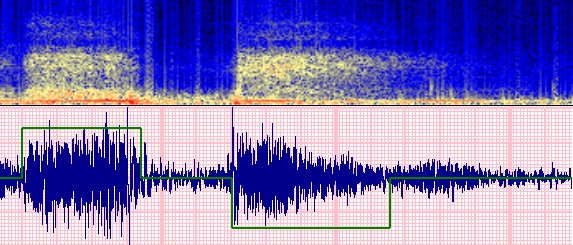
• spectrogramme (spectrogram): il s’agit d’une représentation dans laquelle le temps figure en abscisse, la fréquence
en ordonnée et l’intensité du signal est représentée par une palette de couleurs; la figure ci-dessous représente un spectrogramme
prélevé à l'aide d'un prototype Alcatel-Lucent de stéthoscope et généré par le logiciel propriétaire de la société. le spectrogramme,
c'est la courbe du haut, que j'ai placé en regard du phonopneumogramme précédent. Il s'agit du męme enregistrement pulmonaire d'un
individu sain. Le choix des couleurs peut ętre configuré. Sur cet exemple, on va du bleu foncé (aucune énergie) au rouge (énergie maximale)
en passant par le jaune.
4. Techniques de capture
Enregistrer le son de manière adaptée est une étape importante qui précède la phase d’analyse du signal. Typiquement la chaîne
de capture du son comprend les éléments suivants:
• capture du son : le positionnement du microphone est important; en effet la cage thoracique agit comme un atténuateur et un filtre passe-bas;
• amplification du signal;
• filtrage, échantillonnage, numérisation, codage;
• réduction des bruits (bruit cardiaque, frottement de la membrane, bruit ambiant);
• enregistrement du son documenté.
L’article de Cheetham et al. rappelle ces points importants, relatifs à la numérisation des enregistrements des
sons auscultatoires.
4.1. Acquisition
Il existe différentes méthodes et outils de capture du son.
• utilisation d’un seul micro: il s’agit de la méthode la plus couramment utilisée. Le capteur est généralement un micro électret,
la fréquence d’échantillonnage est le plus souvent celle qui est utilisée pour les codecs pour la téléphonie (8 kHz). Vient ensuite
une conversion
analogique/numérique avec une résolution de 16 bits. D’aucuns utilisent un accéléromètre, moins sensible au bruit ambiant,
mais moins performant que le microélectret;
• utilisation de plusieurs microphones et représentation 3D: cette technique permet l’identification des zones à l’origine des sons.
Il s’agit d’une méthode dynamique pour dévoiler des propriétés structurelles et fonctionnelles à des fins de diagnostic; le pionnier
de cette technique est le Dr. Raymond Murphy. On retrouve une bonne description de la méthode sur son
site
• émission d’un son et analyse de sa propagation: cette technique consiste à émettre un
son depuis un haut-parleur introduit dans la bouche du patient. Elle s’appuie sur une analyse des caractéristiques du signal
propagé à travers
les voies respiratoires et la cavité thoracique. Les paramètres analysés sont les ratios d’énergie,
le délai de latence du signal, et les
fréquences dominantes.
On se rapproche là des pratiques anciennes, décrites par Laënnec et ses élèves, qui consiste à effectuer une percussion sur le thorax, pour
ensuite écouter les bruits générés par l'onde sonore qui traverse les tissus.
On retrouve également une technique similaire, mais dans une application très éloignée, dans la "sismique",
pour la recherche de pétrole au traves des couches géologiques.
On mentionne également la technique qui consiste à appuyer le patient contre une porte
ou toute autre paroi en bois, afin d'amplifier le signal acoustique.
4.2. Filtrage et suppression des bruits cardiaques
Les sons cardiaques peuvent introduire des perturbations lors de l’analyse des sons pulmonaires. Le spectre des sons cardiaques est situé entre
20 et 40000 Hz. Mais un filtre passe haut ne peut pas ętre une solution pertinente car la majorité des composantes pulmonaires sont
également situées dans cette région. Différentes méthodes ont par conséquent été testées:
• ondelettes,
• filtrage adaptatif avec algorithme des moindres carrés récursifs,
• filtrage temps/fréquence et reconstruction,
• estimation autorégressif / moyenne mobile (AR / MA) en temps/fréquence avec des coefficients d’ondelettes,
• analyse des composantes indépendantes
• méthodes d’entropie.
Le filtre proposé par Bahoura et al. est basé sur une transformée en ondelettes par paquets, et l’utilisation de deux filtres qui sont
définis dans le domaine fréquentiel et le domaine temporel.
Ce filtre fournit des résultats plus fiables et plus efficaces que ceux de ses rivaux;
les résultats expérimentaux ont démontré de très bonnes performances. De plus, la technique proposée permet
de mieux préserver les caractéristiques
des signaux stationnaires (sons normaux et sibilants).
Dans l’article de Yadollahi et al., l’atténuation des bruits cardiaques est obtenue à l’aide d’un simple filtre passe-bande
[50 Hz, 2500 Hz]. C'est curieux,
dans la mesure oů on est en plein dans une plage de fréquence de signaux pertinents dans le domaine pulmonaire.
Parmi ces méthodes, les meilleurs résultats ont été obtenus à l’aide
du filtrage adaptatif, du filtrage temps/fréquence et de
l’estimation AR/MA.
4.3. Suppression des sons parasites
Au-delà des bruits du coeur qui sont prélevés en męme temps que ceux des poumons (on peut demander au patient de ne pas
respirer lorsque l'on écoute son coeur, on peut difficilement demander l'inverse !), il convient également de filtrer les bruits ambiants.
Ce traitement peut ętre réalisé de deux manières différentes:
• la réduction du bruit par filtrage adaptatif (suppression du bruit blanc gaussien, du signal vocal, des erreurs de mesure);
• la réduction du bruit par paquets d’ondelettes (méthode de Donoho).
Des techniques plus récentes s’appuient sur l’utilisation simultanée de plusieurs capteurs.
5. Caractéristiques des sons pulmonaires
Il est généralement admis que la fréquence des sons pulmonaires se situe dans la plage 50–2500
Hz, celle des sons trachéaux pouvant aller jusqu’à 4000
kHz, ce qui permet de définir une fréquence d’échantillonnage à 8
kHz (théorème de Shannon). Les sons anormaux peuvent ętre divisés en deux sous classes:
• les sons continus ou stationnaires tels que les sibilants, les ronchis;
• les sons discontinus ou non stationnaires tels que les crépitants fins et gros.
Parmi les sons pathologiques, on citera aussi les squawks, les ronflements, et les stridors. Nous allons détailler les caractéristiques
des deux bruits les plus étudiés : les sibilants et les crépitants.
5.1. Caractéristiques des cycles respiratoires
Bahoura propose sa définition des sons caractéristiques de l’inspiration
et de l’expiration. Il situe le spectre des sons trachéaux entre 60 et 600 Hz pour l’inspiration et entre 60 et 700
Hz pour l’expiration.
Il propose ensuite une transformée de Fourier à 4096 points et représente ensuite le signal respiratoire sous deux formes:
• la méthode "chute d’eau" avec une représentation du spectre en trois dimensions (amplitude, fréquence, temps);
• la méthode du spectrogramme déjà évoquée.
Ces représentations permettent généralement une bonne visualisation du cycle respiratoire.
Nous avons développé un outil permettant ces visualisations en temps réel. C'est cet outil qui a été utilisé pour générer
toutes les représentations qui sont fournies ici, ainsi que dans de nombreux articles rappelés dans la rubrique
Publications.
5.2. Caractéristiques des sibilants
L’identification des sons pulmonaires continus anormaux tels que les sibilants dans le cycle respiratoire est d’une grande importance pour le
diagnostic des pathologies liées à l’obstruction des voies aériennes respiratoires.
Sovijarvi et al. indiquent que les sibilants peuvent présenter des composantes acoustiques indiquant, non seulement la présence d’anomalies
dans le système respiratoire, mais également la sévérité et la localisation des obstructions des voies aériennes les plus fréquemment rencontrées
dans l’asthme et les sténoses respiratoires.
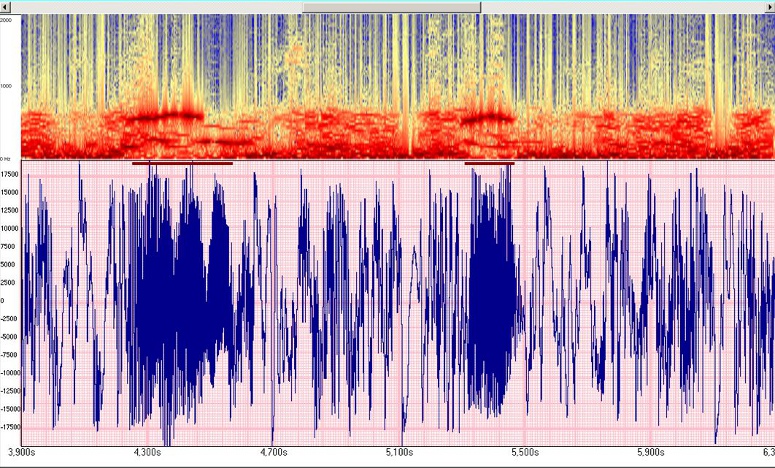
L'image ci-dessus est celle de la respiration d'un nourrisson atteint de bronchiolite. Le trait noir horizontal est le marqueur de l'outil
Alcatel-Lucent qui a détecté un sibilant.
Les sibilants, que Laënnec appelle râles sibilants secs, ou sifflements sont des sons d’une durée supérieure (selon les articles)
à 50 ou à 100 ms et inférieure à 250 ms.
La plage de fréquence des sibilants est comprise selon les auteurs entre 100 et 2500 Hz avec
un pic de fréquence fondamentale entre 100 (ou 400) et 1000 Hz
(ou 1600 Hz). Selon certains auteurs, les sibilants
ont une fréquence dominante supérieure à 400 Hz, par opposition aux ronchis dont la fréquence
dominante est située à 200 Hz et moins. Enfin, chez les sujets
asthmatiques, les sibilants sont présents dans l’expiration, avec
une durée comprise entre 80 et 250 ms.
Albers et al. et Meslier et al. associent les sibilants aux pathologies suivantes: infections telles que le croup (infection
qui touche habituellement les enfants d’un à trois ans), toux
asphyxiante, laryngite, trachéobronchite aiguë, laryngomalacie, trachéo- ou bronchomalacie;
tumeurs laryngales ou trachéales; sténoses trachéales; sténoses laryngales émotionnelles; aspiration
d’un corps étranger; compression des voies aériennes et asthme.
5.3. Caractéristiques des crépitants
Les crépitants correspondent à des sons courts explosifs,
généralement associés à des problèmes pulmonaires du type
infection pulmonaire (pneumonie), oedème pulmonaire, etc ...
• Ils sont générés lors de l’ouverture des voies
aériennes qui ont été fermées anormalement pendant la phase
d’inspiration, ou lors de la fermeture en fin d’expiration. La
détection des crépitants est importante car leur nombre est une
indication possible de la sévérité d’une affection pulmonaire,
• Mais plus que leur nombre, leur positionnement dans le
cycle respiratoire, et la forme de leur signal sont caractéristiques
des cas de pathologies pulmonaires.
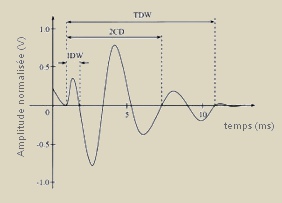
Forme d’onde d’un crépitant
IDW (largueur de déflexion initiale) est l’instant du début du crépitant jusqu’ŕ la première déflexion.
2CD représente la durée de deux cycles ŕ partir du début du crépitant. TDW correspond ŕ la durée totale du signal crépitant.
Les crépitants débutent
généralement par une déflection forte, suivie d’une onde sinusoďdale
longue et amortie telles que représentées par la
figure ci-dessus.
Il est admis que la durée des crépitants est inférieure ŕ
20 ms et que leur fréquence est comprise entre 100 et 200 Hz.
Par ailleurs, les crépitants peuvent ętre divisés en deux familles:
• les crépitants fins (que Laënnec appelle râles humides ou crépitations) qui sont caractérisés, selon les auteurs
par: IDW = 0,50 ou 0,90 ms, 2CD = 3,3
ou 6 ms, et TDW= 4 ms. Ils sont exclusivement inspiratoires;
• les gros crépitants (le râle muqueux ou gargouillement chez Laënnec) qui sont caractérisés par:
IDW = 1,0 ms,
2CD = 5,1 ms,
TDW = 6,7 ms pour et par
IDW = 1,25 ms,
2CD = 9,50 ms pour Vannuccini et al.; ils sont généralement
inspiratoires, mais peuvent également ętre expiratoires.
L’article Piirila et al. nous indique les principales
pathologies dans lesquelles on retrouve des crépitants:
• fibroses pulmonaires : 2CD inférieur ŕ 8 ms, fréquence de l’ordre de
200 Hz;
• asbestoses : durée des crépitants d’environ 10 ms;
• bronchiectasies : 2CD supérieur à 9 ms, ils apparaissent plutôt
tardivement dans le cycle inspiratoire et ont une durée relativement longue par rapport à la phase respiratoire;
• bronchopneumopathies chroniques obstructives (BPCO): 2CD
supérieur à 9 ms, débutent généralement tôt dans l’inspiration et se terminent avant le milieu de l’inspiration
(voir l'image et le son correspondant);
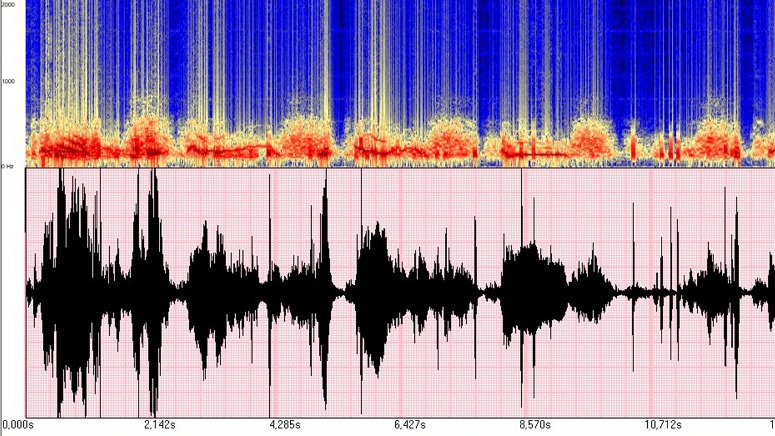
• insuffisances cardiaques (2CD >10 ms);
• pneumonies : 2CD entre neuf et 11 ms, ils apparaissent en milieu d’inspiration;
• et sarcoďdose.
6. Détection des marqueurs connus
à ce jour, les marqueurs connus et décrits dans la littérature sont les crépitants et les sibilants.
Différentes méthodes d’analyse ont été exploitées et décrites. On citera l’analyse temporelle de l’onde pour la recherche des crépitants,
et l’analyse fréquentielle (transformée de Fourier, spectrogramme en 2D ou en
3D, sonogramme) utilisés dans la détection des sibilants.
Dans les
techniques d’analyse spectrale, les principaux paramètres sont la fréquence moyenne du spectre de puissance, la fréquence de la puissance
maximale, le nombre de pics dominants, le facteur de décroissance exponentielle.
Enfin, l’analyse temps–amplitude et temps–fréquence est
classiquement réalisée à l’aide de transformée en ondelettes.
Parmi les solutions les plus récentes, on citera l’utilisation d’un perceptron
multicouche d’un réseau de neurones, des algorithmes génétiques et une solution hybride entre les deux.
La recherche des paramètres est effectuée par
méthode d’apprentissage.
Guler et al. constatent que la solution
hybride est la plus performante.
Murphy et al. montrent
qu’un analyseur multicanaux (plusieurs capteurs utilisés simultanément)
est capable de détecter des différences significatives
entre les sons pulmonaires de patients atteints de pneumonie et
les patients ne présentant pas de symptômes.
6.1. Détection des sibilants
On trouve de nombreux articles décrivant
une technique d’analyse spectrale pour la détection
des sibilants. En effet, la caractéristique essentielle de ces sons
réside dans les pics d’énergie qui peuvent ętre visualisés dans le
spectre. Les limites de cette méthode résident dans l’existence,
dans les sons pulmonaires normaux, de pics similaires à ceux
caractérisant les sibilants, ce qui entraîne un taux élevé de fausses
détections.
Les difficultés rencontrées dans l’automatisation de
la détection des sibilants peuvent ętre surmontées par une analyse
conjointe temps–fréquence. Le principe est le suivant : la
détection dans le domaine fréquentiel d’un pic susceptible de
correspondre à un sibilant sera suivie d’un second test dans
le domaine temporel pour confirmer les vrais sibilants et rejeter
les faux.
Selon Homs-Cobrera et al., les paramètres
significatifs sont la fréquence et le nombre moyen de sibilants
détectés. Ils utilisent les paramètres : nombre de sibilants, fréquence
moyenne du sibilant avec pic de puissance le plus élevé,
fréquence moyenne du sibilant avec pic de moyenne puissance
le plus élevé, fréquence moyenne, emplacement des sibilants.
Les paramètres sont définis après avoir divisé le champ de fréquence
en bandes de 50 Hz.
De plus, l’algorithme cité montre
qu’il y a une forte corrélation entre le nombre de sibilants
détectés et l’amplitude du signal; cela est dű ŕ la dépendance
entre le facteur de normalisation et les seuils des rčgles floues.
Les spectrogrammes fournissent une représentation visuelle de
la localisation des sibilants. Cependant, ces informations ne
s’avčrent pas ętre suffisantes pour caractériser objectivement les
sons. Une autre procédure de détection automatique des sibilants
a été proposée.
Elle est basée sur la décomposition par
paquets d’ondelettes, en deux étapes, comportant en premier
lieu, une détection fréquentielle avec extraction des sibilants,
puis aprčs transformation inverse et reconstruction du signal
utile, une détection temporelle permettant lŕ aussi d’éliminer les
fausses détections résultant d’une superposition des domaines
spectraux de certains sons normaux avec des sibilants.
à partir
des spectrogrammes générés par les sons enregistrés, Lin et al.
réalisent un filtrage bilatéral 2D pour la préservation du lissage
aux bords.
Les résultats indiquant une haute efficacité
du
système, les auteurs ambitionnent d’utiliser ce système pour le
monitoring de patients asthmatiques et l’étude de la physiologie
des voies aériennes.
L’article de Meslier et Charbonneau
s’appuie également sur l’analyse et la quantification automatique
des sibilants à partir de l’analyse spectrale.
Ces algorithmes sont
basés sur la définition d’un seuil au-dessus duquel la présence de
pics dans le domaine fréquentiel, est caractéristique du sibilant.
Ces seuils sont différents selon les articles (on trouvera ainsi la
caractérisation d’un pic par une puissance 15 fois supérieure à la
moyenne courante, ou trois fois supérieure à la valeur moyenne).
Toutes ces études définissent des seuils constants, basés sur des
mesures de puissance. La référence confirme les mauvaises
détections de sibilants à l’aide d’analyse fréquentielle seule. Cet
article décrit un nouvel algorithme basé sur la « modélisation
auditive », appelé frequency and duration dependent threshold (fddt) algorithm.
Les paramètres de fréquence moyenne et durée
de sibilants sont obtenus automatiquement. La notion de seuil dépendant de la fréquence et de la durée a été introduite dans le
nouvel algorithme pour la détection de sibilants.
Le seuil n’est
plus basé sur la puissance globale mais sur la puissance correspondant
à une plage de fréquence particulière. Le choix de
l’énergie au lieu de la puissance a été fait suite aux résultats des
études antérieures indiquant qu’un seuil énergétique est plus
adapté à la détection de sons de courtes durées (inférieure à
200 ms). De leur côté, certains auteurs s’appuient sur une
méthode de transformée en ondelettes continues, combinée avec
un seuil dépendant de l’échelle, et semble avoir un taux de bonne
reconnaissance plus élevé.
| Méthodologie |
Paramètres |
Taux de classification correcte (%) |
| Analyse temps–fréquence |
Bande passante gaussienne, fréquence des pics, largueur
de déflexion totale, largueur de déflexion maximal |
87,78 |
| Analyse temps–fréquence |
Bande passante gaussienne, fréquence des pics, largueur
de déflexion maximal |
90,5 |
|
| Modélisation prony |
Paramètres du modèle de Prony
Coefficients autorégressifs |
63,89 |
| Transformée en ondelettes |
échelle de l’ondelette mère
Transformée en ondelettes basée sur la dimension fractale
Transformée en ondelettes stationnaire/non stationnaire |
93,9
ND
ND |
|
| Règles floues |
27 règles floues |
ND |
| Réseau de neurones artificiels |
Coefficients autorégressifs, coefficients d’ondelette,
paramètres de crépitants |
ND |
| Mode de décomposition |
empirique Instrinsic mode function |
ND |
6.2. Détection de crépitants
L’analyse des crépitants est constituée de trois étapes principales:
• un filtre de suppression de bruit est appliqué pour supprimer
le bruit résiduel stationnaire dans un signal non stationnaire;
• une recherche de la forme d’onde correspondant au crépitant;
• les crépitants détectés sont classifiés en deux categories : les
crépitants fins et les gros crépitants.
Kayha et Yilmaz proposent un système automatique
de détection et de classification des crépitants. Le
système proposé utilise un filtre stationnaire/non stationnaire
et la transformée en ondelettes par paquets (ou WPST–NST)
qui permet d’isoler les crépitants des sons vésiculaires. Celui
de Kawamura a montré l’existence d’une corrélation
entre les sons respiratoires et la détermination des tomographies
informatiques haute résolution.
Deux paramètres, deux cycles,
et la largeur de la déflexion initiale des crépitants ont été induits
par l’analyse du signal temporel.
Kayha et al. décrivent un
système basé sur l’augmentation des phénomènes transitoires
à l’aide d’un filtre adaptatif et l’implémentation d’opérateur
non linéaire aux compositions en ondelettes du son pulmonaire.
L’article de Yeginerand et al. décrit également l’utilisation
de réseaux d’ondelettes pour modéliser les crépitants pulmonaires.
L’algorithme proposé par Vannucci et al. utilise un
filtre stationnaire–non stationnaire flou (FST–NST). Les résultats
de la séparation sont relativement fiables.
Le filtre FST–NST
a été appliqué à des sons provenant de trois bases de données.
Tout d’abord, les crépitants ont été séparés du sons vésiculaire.
Puis, 27 règles floues de type « si, alors » ont été utilisées. L'auteur
détecte des crépitants et les sons intestinaux par une analyse
de la dimension fractale des enregistrements.
Les résultats
semblent concluants et, de plus, robustes au bruit. La comparaison
des résultats de différentes méthodes est résumée dans le
tableau ci-dessus.
Les meilleurs résultats de classification sont obtenus en utilisant
l’analyse par ondelettes. Les représentations des paramètres
de Prony indiquent une corrélation entre le type de pathologie,
l’occurrence des crépitants par rapport au volume pulmonaire et
la fréquence de Prony.
6.3. Détection du cycle respiratoire
Afin de fournir des résultats exploitables, l’information doit
toujours ętre ramenée à un cycle respiratoire. Il y a donc
un intéręt certain dans la détection automatique des phases (inspiration/
expiration).
Moussavi et al. utilisent la moyenne
de puissance spectrale du signal respiratoire et la différence
entre la puissance spectrale du signal trachéal et celle du signal
pulmonaire pour détecter les phases respiratoires. Les résultats
ont indiqué un taux de classification correcte situé entre
31 et 69%.
En outre, la différence entre la moyenne de puissance
spectrale inspiratoire et expiratoire, dans une tranche
de fréquence comprise entre 150 et 450 Hz est au maximum
de 10 dB.
Cette méthode fonctionne très bien avec des sons
artificiels ; cependant, elle ne permet pas une réelle classification
des sons. Enfin, dans la référence, il est proposé
de qualifier les sons en utilisant la dimension fractale et un
paramètre appelé variance fractal dimension.
Guler et al. quant à eux
utilisent une classification en six phases : début, milieu, fin
d’inspiration, et début, milieu, fin d’expiration ; cette méthode
s’appuie sur l’utilisation d’un « classifieur » multicouches. Les
caractéristiques extraites sont les paramètres autorégressifs et les
coefficients cepstaux. Le développement d’un tel outil rencontre
deux difficultés majeures :
• les signaux respiratoires ne sont pas stationnaires à cause du
changement de volume dans les poumons ;
• les sons respiratoires présentent une grande variabilité en
fonction de l’âge, de la masse, du stade d’évolution de la
pathologie.
L’article de Guler et al. se base sur un perceptron multicouches.
Il obtient environ 60% de bonne reconnaissance pour
la phase experte sur les segments individuels.
Pour obtenir ce résultat, il
utilise une autre caractéristique des signaux pulmonaires :
la puissance spectrale des sons pulmonaires pendant la phase
d’inspiration est supérieure à celle de la phase d’expiration. Cette
caractéristique peut ętre utilisée seule pour permettre la détection
de phases.
De la même façon, Chuah et Moussavi utilisent un calcul
de la valeur moyenne de la puissance spectrale pour qualifier
le cycle respiratoire. Cette analyse est complétée par un calcul
de la valeur moyenne de la puissance spectrale trachéale afin de
déterminer le début des respirations.
Carlos et Verbandt utilisent
deux réseaux de neurones indépendants (ANN):
l’un pour les
phases d’inspiration, et l’autre pour celles d’expiration. Au
préalable, un prétraitement est effectué en normalisant le signal
en amplitude entre zéro et un.
L’étape suivante met en jeu des
ANN avec une couche cachée. Les paramètres sont obtenus à
l’aide d’algorithmes d’apprentissage utilisant des techniques de
backpropagation. Ensuite, un post-traitement est appliqué ; il
consiste à supprimer certains « 1 » qui se situent entre au moins
cinq « 0 » et inversement. Ces techniques ont été appliquées sur
28.000 sons enregistrés à l’aide de pléthysmography inductive (mesure de volume)
ou de jauges de contraintes. Les résultats avoisinent les 98% de
réussite.
6.4. Classification des sons
En médecine pulmonaire, il n’existe pas de modèle universel
ou de seuil des paramètres indiquant ou non la présence
d’une pathologie.
C'est un peu la raison pour laquelle Zheng et al. proposent d’établir
un modèle personnalisé, combinant l'information provenant des
sons et d'autres mesures réalisées sur le patient. Leur objectif est de
reconnaître un modèle de son pulmonaire.
La méthode appliquée
a été divisée en deux étapes : caractériser les variables extraites
de la forme d’onde des sons pulmonaires et les variations de
ces paramètres; cela fournit une information sur les variations
des modèles.
Guler et al. se focalisent sur les techniques
d’intelligence artificielle. Ils combinent algorithme génétique
et réseau de neurones. En premier lieu, ils sélectionnent des
cycles respiratoires complets, auxquels ils appliquent une power
spectral density (PSD) de 256.
Puis, un perceptron multicouche
est appliqué pour détecter la présence ou l’absence de sons
adventices (crépitants ou sibilants).
La recherche des paramètres
optimaux a été réalisée par méthode d’apprentissage. Chaque
son est associé à plusieurs caractéristiques et à un diagnostic.
Cent vingt-neuf caractéristiques spécifiques ont été recensées
(PSD0. . . PSD128) et différentes règles d’apprentissage ont
été utilisées pour associer caractéristique et diagnostic. Dans
la référence, les auteurs réalisent une comparaison entre
k-NN et
ANN (réseau de neurones artificiels).
Ils utilisent différentes
fonctions extraites du signal respiratoire. En fait, chaque cycle est divisé en six segments avec trois fonctions : coefficient
autorégressif, coefficient en ondelettes et paramètres de
crépitants.
Les paramètres de crépitants sont
ajoutés aux caractéristiques observées afin d’augmenter les
performances de la classification. Cette amélioration des performances
a été confirmée par les tests réalisés. L’étude
se focalise sur quatre pathologies: l’asthme, les bronchiectasies,
la BPCO et la pneumonie.
Le son est divisé en six
sous-phases : début (30%), milieu (40%), fin (30%) d’inspiration
et expiration.
Les expérimentations sont appliquées à chaque
sous-phase. Des classifieurs neuronaux (perceptrons multicouches
avec couche cachée de dix noeuds) sont utilisés avec
les paramètres suivants:
• paramètres autorégressifs,
• prédiction d’erreur,
• durée des ratios inspiration / expiration.
Les poids et
valeurs du perceptron sont mis à jour à l’aide de l’algorithme
d’optimisation de Levenberg–Marquardt, qui est l’un des plus
rapide. Puis, la classification est réalisée en trois étapes :
• pathologique / sain,
• restrictive / obstructive,
• classification entre les
pathologies (asthmes, bronchiectases).
La fiabilité est calculée
«nombre total de classification correct / nombre total de
segments».
Finalement, les performances de classification avoisinent
les 70 à 80%.
L’étude décrit une méthode de
prétraitement visant à réduire la taille des modèles d’entré
dans le réseau de neurones, et à augmenter la performance
d’estimation du classifieur.
Les résultats indiquent que les ondelettes
sont des capteurs significatifs du signal et extraient des
paramètres importants.
Cohen et al. réalisent une classification
des sons normaux et pathologiques en deux étapes :
prédiction linéaire des coefficients et enveloppe énergétique.
Sept types de sons respiratoires ont ainsi été classifiés, parmi
lesquels quatre sons normaux : son vésiculaire, son bronchique,
son bronchovésiculaire et sons trachéal. Les fonctions extraites
sont FFT, PDS, estimation par moyenne de prédiction linéaire.
Cependant, dans cette étude, une décision manuelle des inspiration /
expiration a été réalisée. Les principaux objectifs sont
les suivants : caractériser de façon quantitative plusieurs sons
respiratoires et fournir une méthode de classification automatique.
Enfin, le diagnostic est réalisé par un médecin et est
basé sur l’analyse des sons associée à d’autres éléments de
diagnostic.
Sur 105 expérimentations, seules cinq ont généré
des erreurs. Dokur et al. utilisent les transformées en
ondelettes. Les meilleurs échantillons sont sélectionnés par
programmation dynamique et un réseau de neurone Grow
et Learn est utilisé pour la classification. Le processus de
décision est effectué en trois étapes : normalisation, extraction
de caractéristiques, classification par réseau de neurones.
Les perceptrons multicouches couramment utilisés dans le traitement
du signal biomédical présentent trois inconvénients
majeurs :
• la rétropropagation de l’algorithme est trop longue durant la
phase d’apprentissage;
• le nombre de noeuds dans les couches cachées doit ętre défini
avant la phase d’apprentissage;
• la rétropropagation de l’algorithme doit prendre en compte le
minimum local, qui diminue les performances du réseau.
7. Facteurs influençant la mesure
Il existe des éléments perturbateurs à l’analyse du signal
auscultatoire, qui modifient les résultats et rendent plus
compliquée la comparaison des résultats entre les différentes
équipes de recherches. Parmi ceux-ci, il faut retenir l’âge
et la corpulence du patient, le changement du volume d’air dans
les poumons, le point de prise du son, le débit de ventilation,
la position du patient, et les caractéristiques de l’équipement de
mesure.
7.1. Âge et corpulence
La différenciation liée à l’âge est surtout vraie pour les enfants
en bas âge. Elphick et al. notent que l’évaluation au stéthoscope
est peu fiable pour la détection des sibilants, et autres
crépitants; en effet, les bruits respiratoires audibles dans
la petite enfance possèdent des caractéristiques acoustiques distinctes
de celles habituellement observées chez l’adulte.
Mazic
et al. proposent donc d’utiliser des méthodes plus objectives
pour la détection automatique de sibilants
7.2. Changement de volume d’air dans les poumons
La caractérisation statistique du processus évolue dans un
cycle respiratoire. En effet, les signaux respiratoires
sont non stationnaires, notamment à cause du changement du
volume pulmonaire et du niveau de flux dans un cycle.
Ainsi, pour interpréter correctement les résultats, il est conseillé
de se ramener au volume d’air pulmonaire.
7.3. Standardisation du protocole de mesure
Afin de pallier à ces limitations, il a été proposé de définir
une sémiologie adaptée à la collecte et à l’analyse de sons
auscultatoires. Ces travaux ont conduit à une proposition de standardisation
proposée par le projet européen CORSA, qui
décrit les points d’auscultation, le type de capteurs, le filtrage, la
fréquence d’échantillonnage, la technique de FFT, la définition
d’une moyenne du spectrogramme et l’utilisation de taux de flux
standards.
8. Conclusions et perspectives
Un enregistrement réalisé dans de bonne condition et avec un
équipement adapté est la première étape pour une bonne analyse
des sons.
L’analyse automatique et le traitement des sons auscultatoires
pulmonaires permettent ensuite d’obtenir une analyse
objective du signal, et une possibilité de comparaison des sons,
de suivi de l’évolution d’une pathologie dans le temps. Le traitement
du signal devrait, de plus, permettre de découvrir de
nouvelles caractéristiques des sons adventices jusqu’alors non
perceptibles à l’oreille humaine.
L’état de l’art met en lumière
les nombreuses méthodes appliquées à l’analyse des sons ; ces
méthodes fournissent des résultats très encourageants pour aller
vers une aide au diagnostic toujours plus fiable et utile au patient
et au médecin.
|
